AWS Analytics services
Intro¶
AWS Analytics services
Description¶
AWS offers a wide range of analytics services, each designed for specific use cases. Here's a brief comparison of some of them:

| AWS Service | Optimized For | Description |
|---|---|---|
| Amazon Athena | Interactive analytics | Allows users to analyze data in Amazon S3 using standard SQL. |
| Amazon Redshift | Data warehousing | A fully managed, petabyte-scale data warehouse service in the cloud. |
| Amazon Managed Service for Apache Flink | Real-time analytics | Fully managed service that makes it easy to build and run applications using Apache Flink. |
| Amazon OpenSearch Service | Operational analytics | Makes it easy to deploy, secure, and operate OpenSearch clusters at scale. |
| Amazon QuickSight | Dashboards and visualizations | A fast, cloud-powered business intelligence service that makes it easy to deliver insights to everyone in your organization. |
| Amazon Glue DataBrew | Visual data preparation | A visual data preparation tool that makes it easy to clean and normalize data for analytics and machine learning. |
| Amazon Managed Streaming for Apache Kafka (Amazon MSK) | Real-time data movement | A fully managed service that makes it easy to build and run applications that use Apache Kafka to process streaming data. |
| Amazon Kinesis Data Streams | Real-time data movement | A massively scalable and durable real-time data streaming service.  https://www.youtube.com/watch?v=6SUfMEwMUro https://www.youtube.com/watch?v=6SUfMEwMUro |
| Amazon Kinesis Data Firehose | NEAR-Real-time data movement | The easiest way to reliably load streaming data into data lakes, data stores, and analytics services. |
| Amazon Kinesis Data Analytics | An on-demand data analytics service that allows you to process and analyze streaming data in real time. It provides a serverless experience, so you don't have to provision or manage resources. | Real-time data processing, real-time analytics, IoT data analysis, fraud detection. Amazon Kinesis Data Analytics is the easiest way to analyze streaming data in real-time. You can quickly build SQL queries and sophisticated Java applications using built-in templates and operators for common processing functions to organize, transform, aggregate, and analyze data at any scale. Kinesis Data Analytics enables you to easily and quickly build queries and sophisticated streaming applications in three simple steps: 1 setup your streaming data sources, 2 write your queries or streaming applications and 3 set up your destination for processed data. Kinesis Data Analytics is used to build SQL queries on streaming data. |
| Amazon Kinesis Video Streams | Real-time data movement | Securely streams video from connected devices to AWS for analytics, machine learning (ML), and other processing. |
| Amazon Kinesis Data Streams | A fully managed service for real-time data ingestion and processing. It's designed to handle high-volume, low-latency data streams from thousands of sources. | Real-time data ingestion, data processing, data streaming |
| AWS Glue | Big data processing | A fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. https://www.youtube.com/watch?v=cDDPg_XxPqc&t=2079s |
| Amazon EMR | Big data processing | Like Glue, but more complex, open-source. Need more flexibility and control over their data processing environment. Amazon EMR is the cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. Amazon EMR uses Hadoop, an open-source framework, to distribute your data and processing across a resizable cluster of Amazon EC2 instances. |
| AWS Data Exchange | Data sharing | A data-market. |
| AWS Data Pipeline | A fully managed data orchestration service that simplifies the process of building, scheduling, and monitoring data pipelines. It eliminates the need to manually provision, manage, and scale resources for data movement and transformation. | Data integration, data warehousing, data lake creation, data quality checks, data migration |
| AWS Lake Formation | A fully managed service that makes it easy to set up and manage secure data lakes in Amazon S3. It provides centralized governance and management capabilities for your data lake, including access control, data quality, and data lineage. | Data lake management, data governance, data quality |
See https://aws.amazon.com/getting-started/decision-guides/analytics-on-aws-how-to-choose/?nc1=h_ls
Each service is designed with specific use cases in mind, so the best one for you would depend on your specific needs¹². AWS also provides a decision guide to help determine which AWS analytics services are the best fit for your organization¹.
https://aws.amazon.com/getting-started/decision-guides/analytics-on-aws-how-to-choose/?nc1=h_ls
AWS Lake Formation:¶
AWS Lake Formation can be used to build, secure, and manage data lakes. It helps in centralized access management for data in data lakes.
 Built on top of GLue to add permissions
Built on top of GLue to add permissions
Coarse graned authorization: IAM¶
Important to note that using Lake Formation security model does not mean that we do not need to use IAM. The lake formation permissions model actually works in conjunction with IAM. We use IAM to still grant the coarse-grain permissions to access the catalog, but we use Lake formation to provide all of the fine-grained permissions on the databases tables and columns.
Fine graned authorization: tags and named resources¶
In AWS Lake Formation, the units that are shareable via LF-tags or named resources are Data Catalog resources, which include
- databases,
- tables in database,
- columns in table.
The following two options are available to share the resources in the data lakes with other accounts.
- LF-Tags: Recommended way to manage permissions. To use the Lake Formation tag-based access control (LF-TBAC) method to secure Data Catalog resources, you create LF-Tags, assign them to resources, and grant LF-Tag permissions to principals¹. Only a data lake administrator or a principal with LF-Tag creator permissions can create LF-Tags.
- Named Resources: The Lake Formation named resource method is an authorization strategy that defines permissions for resources². Data lake administrators can assign and revoke permissions on Lake Formation resources².
Both methods allow for fine-grained access control and secure sharing of data within a data lake.
Additional on method
- Data location permissions - required by the AWS Glue Crawlers to access data in data lakes from other accounts. You can use Data location permissions to grant read, write, or execute access to users and roles. For example, you could grant read access to the S3 bucket that contains your data lake to a group of users who need to access the data.
- BUT: For integrated services like Amazon Athena and Amazon Redshift Spectrum, a resource link is required.

With tags one has less management effort of permissions. Permissions are attached to tags.
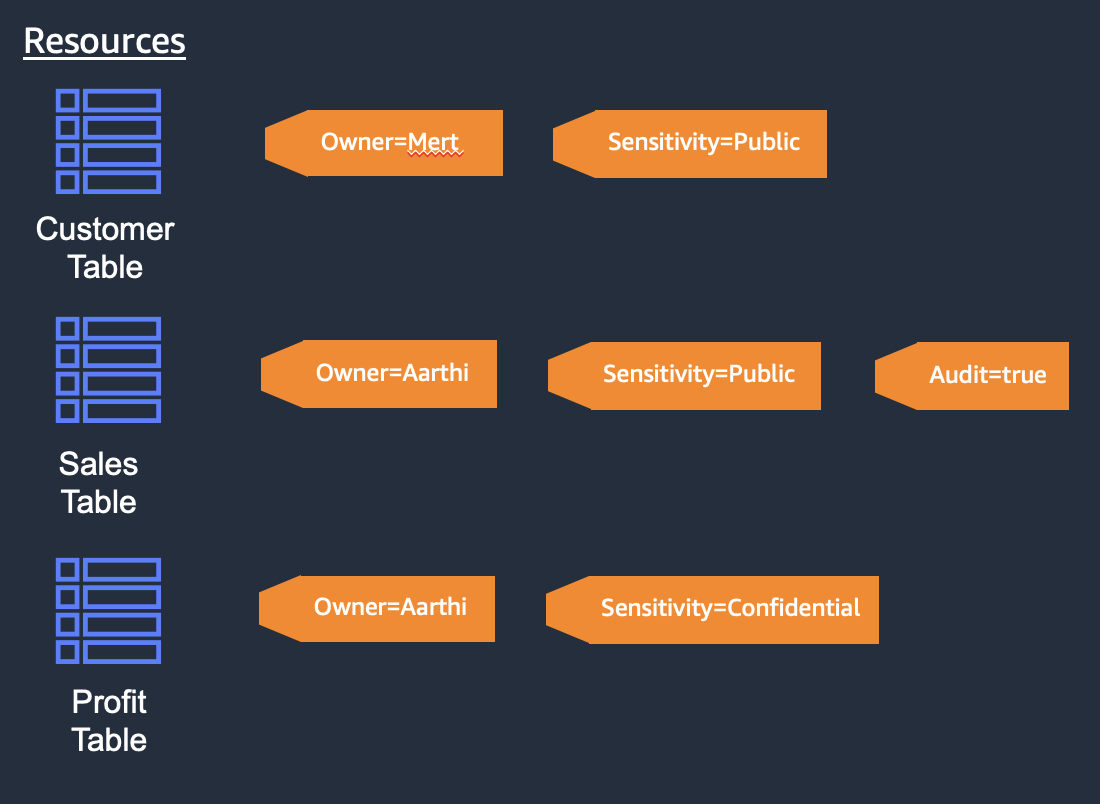
see
- https://aws.github.io/aws-lakeformation-best-practices/lf-tags/basics/
- Managing LF-Tags for metadata access control - AWS Lake Formation. https://docs.aws.amazon.com/lake-formation/latest/dg/managing-tags.html
- Sharing a data lake using Lake Formation tag-based access control and https://docs.aws.amazon.com/lake-formation/latest/dg/share-dl-tbac-tutorial.html
1 LF-TBAC. Lake Formation - tag based access control¶
- Lake Formation tag-based access control (LF-TBAC): This defines lake formation permission using attributes. In lake formation, tags are called LF-tags which grant permission to access databases with external principals, accounts, and AWS Organization. This is a recommended option for sharing databases with external accounts.
2 Named resources¶
- Lake Formation named resources: This grants Lake Formation permissions with a grant option on Data Catalog tables and databases to external AWS accounts, IAM principals, organizations, or organizational units.
Sharing Lake Formation catalog with AWS services¶
A resource link is a data catalog object which is linked to a local or shared database.
Creating a resource link allows integrating with AWS services in other accounts such as Amazon Athena or Amazon Redshift Spectrum to run queries on the shared database.
These AWS services will NOT be able to access directly across cross accounts but using resource links, services can run queries on shared databases in other accounts.
Summary¶
| Option | Use case |
|---|---|
| Named resources | Create easily identifiable and reusable references to Data Catalog entities. |
| LF-TBAC | Grant cross-account access to Data Catalog entities. |
| Resource links | Create references to Data Catalog entities in other services. |
For more information on cross account permissions with AWS Lake Formation, refer to the following URLs,
- https://docs.aws.amazon.com/lake-formation/latest/dg/cross-account-permissions.html
- https://docs.aws.amazon.com/lake-formation/latest/dg/resource-links-about.html
Links¶
- (1) Decision Guide for Analytics Services on AWS. https://aws.amazon.com/getting-started/decision-guides/analytics-on-aws-how-to-choose/.
- (2) Data Lakes and Analytics on AWS - Amazon Web Services. https://aws.amazon.com/big-data/datalakes-and-analytics/.
- (3) Decision Guide for Analytics Services on AWS. https://aws.amazon.com/getting-started/decision-guides/analytics-on-aws-how-to-choose/.
- (4) AWS, Azure and GCP Service Comparison for Data Science & AI. https://www.datacamp.com/cheat-sheet/aws-azure-and-gcp-service-comparison-for-data-science-and-ai.
- (5) AWS Data Analytics: Choosing the Best Option for You - NetApp. https://bluexp.netapp.com/blog/aws-cvo-blg-aws-data-analytics-choosing-the-best-option-for-you.
- (6) Compare AWS Trusted Advisor vs. Azure Analysis Services | G2. https://www.g2.com/compare/aws-trusted-advisor-vs-azure-analysis-services.
- Data lake with Cloud Formation - https://medium.com/@sukul.teradata/data-lakes-and-data-integration-with-aws-lake-formation-6bf39416990b
- https://aws.github.io/aws-lakeformation-best-practices/lf-tags/basics/
- Managing LF-Tags for metadata access control - AWS Lake Formation. https://docs.aws.amazon.com/lake-formation/latest/dg/managing-tags.html
- Sharing a data lake using Lake Formation tag-based access control and https://docs.aws.amazon.com/lake-formation/latest/dg/share-dl-tbac-tutorial.html
- https://aws.amazon.com/getting-started/decision-guides/analytics-on-aws-how-to-choose/
- https://aws.amazon.com/getting-started/decision-guides/analytics-on-aws-how-to-choose/?nc1=h_ls